
by: Zank, CEO of Bennett Data Science
Maybe a better title would be, Data Science Exposed. Maybe that’s still not quite right.
I want to talk about how we at Bennett Data Science generally work, and share work, with our clients. I want to show you this because it’s really simple and quite beautiful. It usually brings a lot of satisfaction to new clients. And it’s a method we’ve used to share our work with CEO’s to CTO’s to developers and other data scientists. It’s that simple to understand.
HOW we work is important. Sometimes it’s more important than WHAT we do.
Let me explain.
Consider two cases:
- Jamie opens up her laptop, creates a new tab in her favorite browser, navigates to a company URL, logs in and immediately sees all her work, alongside that of her team. She pulls some data from a cloud-based source and picks up the analysis she started off yesterday.
- Sean opens up his laptop, and opens a terminal screen to start Python. While packages are loading he opens a connection to a company database, runs a query and saves some data locally for an analysis he needs to run.
Jamie and Sean are doing the same work, but in different ways. Let’s look at how.
Both are similar and will eventually reach the same end result, but the HOW is drastically different. In the first case, Jamie is using cloud-based tools to do all the heavy lifting (data processing and analytic model building). Sean, however, must rely on his laptop to handle that same heavy lifting, from the actual computations to pulling and storing the data. At the end of the day, both commit their code to GitHub, where’s it’s trivial to share/review the work.
So, who cares?
We do. A lot, actually. Because fundamentally, we believe it’s preferable to be able to say, your data was never downloaded to our machines. If Jamie processes 5TB of data, there’s nearly no trace of it on her local machine. And if she’s sick and forgets to commit her work to a repository, it’s on a persistent cloud-based disk, and can be retrieved at any time. Your data and your work start and stay that way.
Imagine having real-time access to the work of your entire data science team at a level of granularity that can be understood by the CEO and an analyst. That’s exactly what you’ll have with the tools I’d like to show you here.
Next, I’ll show you how to set up your analytics team for:
- maximum transparency
- minimum exposure to data loss/breech
- the huge upside of having the team know their work can be seen and understood company-wide
That last one is particularly important, as analytics professionals, as much as any other group, yearn to shed the “nerdy” persona sometimes.
The Setup
Here is a minimum setup that you can implement for your team in a half day, if you’re willing to use Google Cloud infrastructure. If not, AWS and Azure offer something similar.
- Set up an online area where your team can create Jupyter Notebooks. If you use, or are willing to use, Google (Cloud) products, you can use Colab, or DataLab. The former is free but has trickier Git integration, and the latter is paid but very inexpensive and somewhat complicated to set up.
- Use GitHub as your repository. They have a feature that allows the Jupyter Notebooks, that so many data scientists use, to be viewed in all their glory, whereas other repositories don’t allow this representation (called nbviewer).
- Be sure your team understands how to pull data from your data stores (S3, Google Cloud Storage, Google BigQuery etc.) directly into their notebooks.
You now have company-wide (if you want) access
Let’s take a look at what a simple notebook looks like, briefly discuss what they can do and how they look on GitHub.
Here’s a screenshot from a typical Jupyter Notebook:
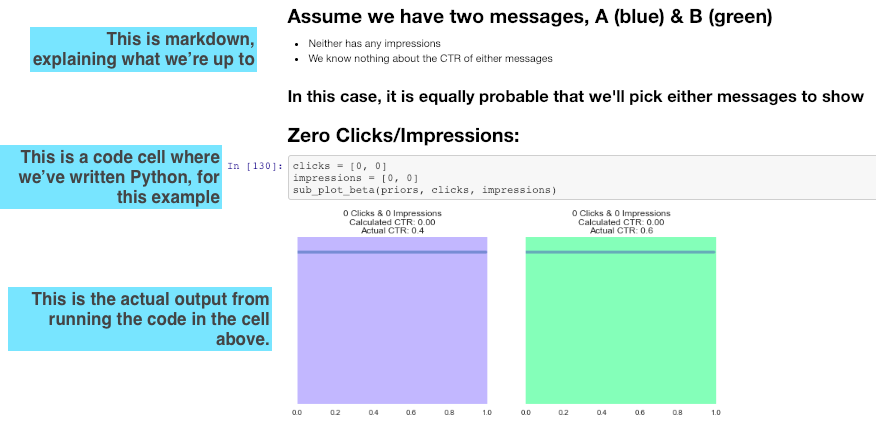
The blue boxes are my comments. This is rendered the same way on GitHub as is in Jupyter, where data science professional spend a lot of time working. In other words, you see what they see!
The markdown makes the coming analysis easy to understand and the inline graphs tell the full story.
In many cases, these notebooks are completely sufficient to show to management or stoke-holders, obviating the additional work generally required by building a slide deck. I’ve personally spend thousands of hours in PowerPoint and, later, Google Slides, putting together a story that could have been produced by default by starting with Jupyter.
Finally
If you use these tools, you’ll have more immediate access to your team, and if a laptop goes missing, no one will have access to your data or analyses, since it never existed on the machine in the first place! You have two things protecting you: the cloud password and your ability to shut down access in seconds. You just can’t do that sort of thing easily on a remote laptop.
I hope this overview helps you understand how data scientists can work in a transparent and more protected way. Please let me know if you have any questions or comments.
Zank Bennett is CEO of Bennett Data Science, a group that works with companies from early-stage startups to the Fortune 500. BDS specializes in working with large volumes of data to solve complex business problems, finding novel ways for companies to grow their products and revenue using data, and maximizing the effectiveness of existing data science personnel. bennettdatascience.com