
Recently I started reading a book called Nonviolent Communication. The book really got me thinking about the intricacies of text and communication; in particular, the ways text can be interpreted and even charged.
This week I want to talk about a topic I’ve spent a bit of time working on and, as long as I’ve done it, always thought was at once trivial and insanely difficult – Sentiment analysis.
Sentiment Analysis
Sentiment analysis is the process of determining the positivity or negativity of a piece of text.
To illustrate the challenge in understanding sentiment, decide for yourself how objectively positive or negative each of these two sentences is:
I hate iPhones but love Samsung phones.
or
I hate Samsung phones but love iPhones.
The sentences use identical words but express two entirely different sentiments about two different companies or devices.
Is either of these sentences positive or negative? Or perhaps are they both at the same time? And how can a computer make sense of texts like this to understand what the reviewer means?
This is only part of the challenges faced by practitioners of Natural Language Processing (NLP), who want to uncover sentiment in these types of reviews or statements.
Three Typical Approaches
There are three typical approaches to sentiment analysis:
- Rule-based: Use a huge database (such as AFFIN) of words rated by their positivity or negativity, scored from -5 for very negative words to +5 for very positive words. In this case, each word gets a score and the overall sentiment of the text is represented by that total score. This approach would rank both of our reviews as having the same sentiment, since both use all the same words.
- Machine learning-based: NLP techniques may be used to understand intent using large volumes of human-labeled text. In this case, sentiment is assessed by subject matter experts and A.I. learns based on what the humans labeled.
- Hybrid approach – this approach blends the two.
The drawbacks of approaches one and two are obvious – rule-based sentiment disregards the order and combination of words. It also misses emotion, tone, and intricacies such as sarcasm.
Imagine trying to extract sentiment from this viewer who loved a show so much that she spent all Saturday indoors and left the following sarcastic review: “What a horrible way to kill an entire Saturday.”
On the machine learning side, the number of edge cases, such as sarcasm or implied sentiment, is astronomical and changes across regions, dialects and time periods.
The Trickiness of Sentiment Analysis
To show just how tricky sentiment analysis is, I turn to MonkeyLearn, who has a page (link) where you can enter some text and receive a positive or negative score along with confidence.
Let’s use the two sentences from above and see if we get identical results (you already know we won’t!)
Using their “product sentiment analysis” tool, here are screenshots:
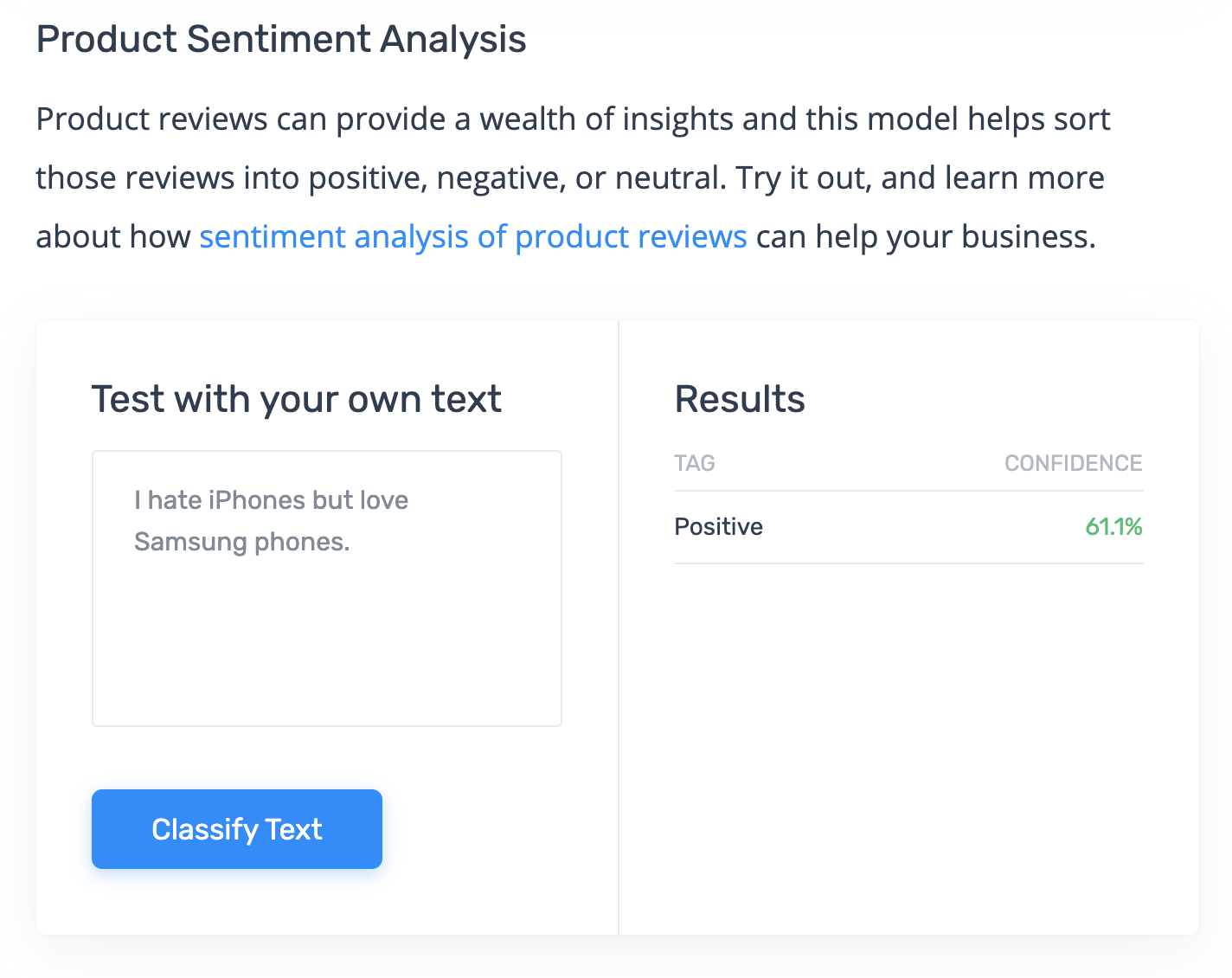
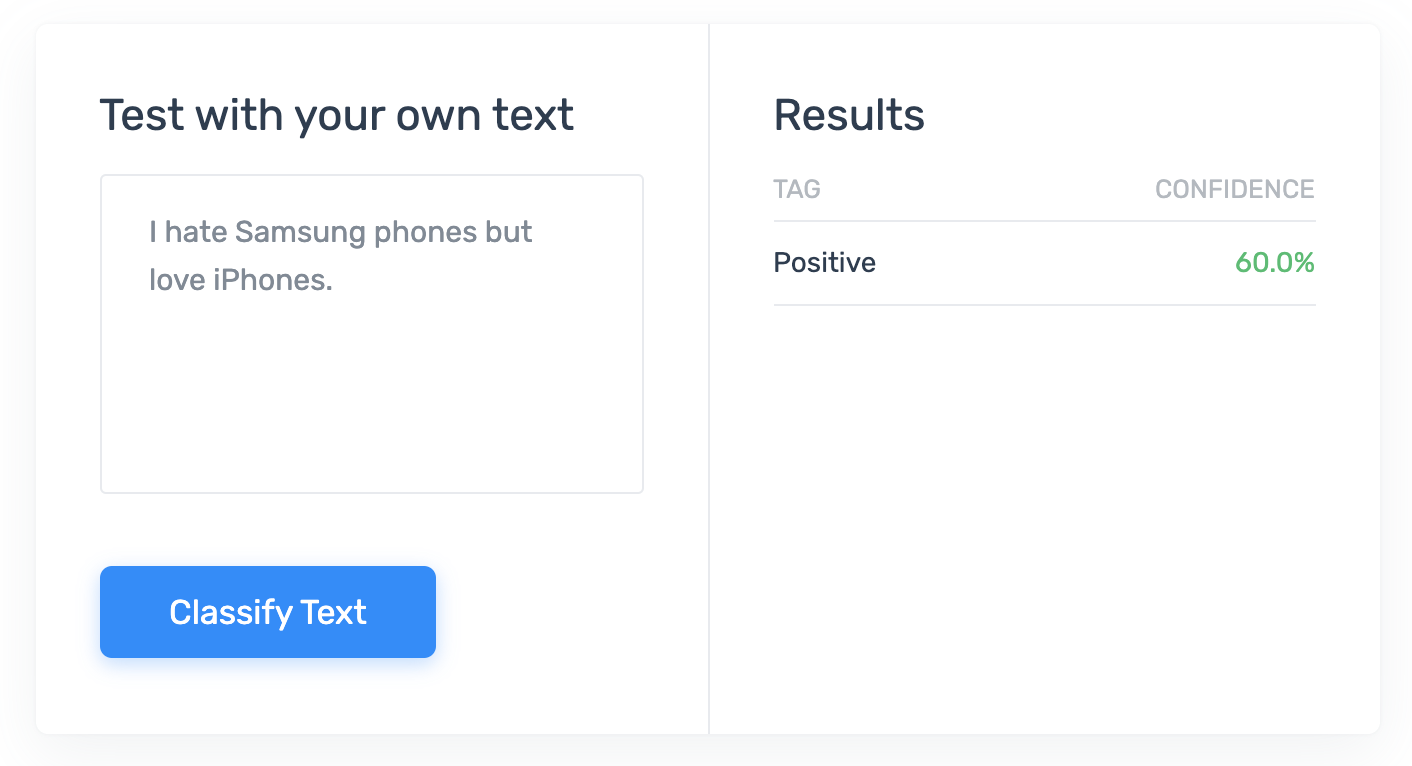
Hmm. How is it possible that by simply swapping the order of the products, I get a different computed sentiment confidence when all the words are the same? Are they doing some sort of named entity recognition that ranks “Samsung phones” higher or lower in sentiment than “iPhones”?
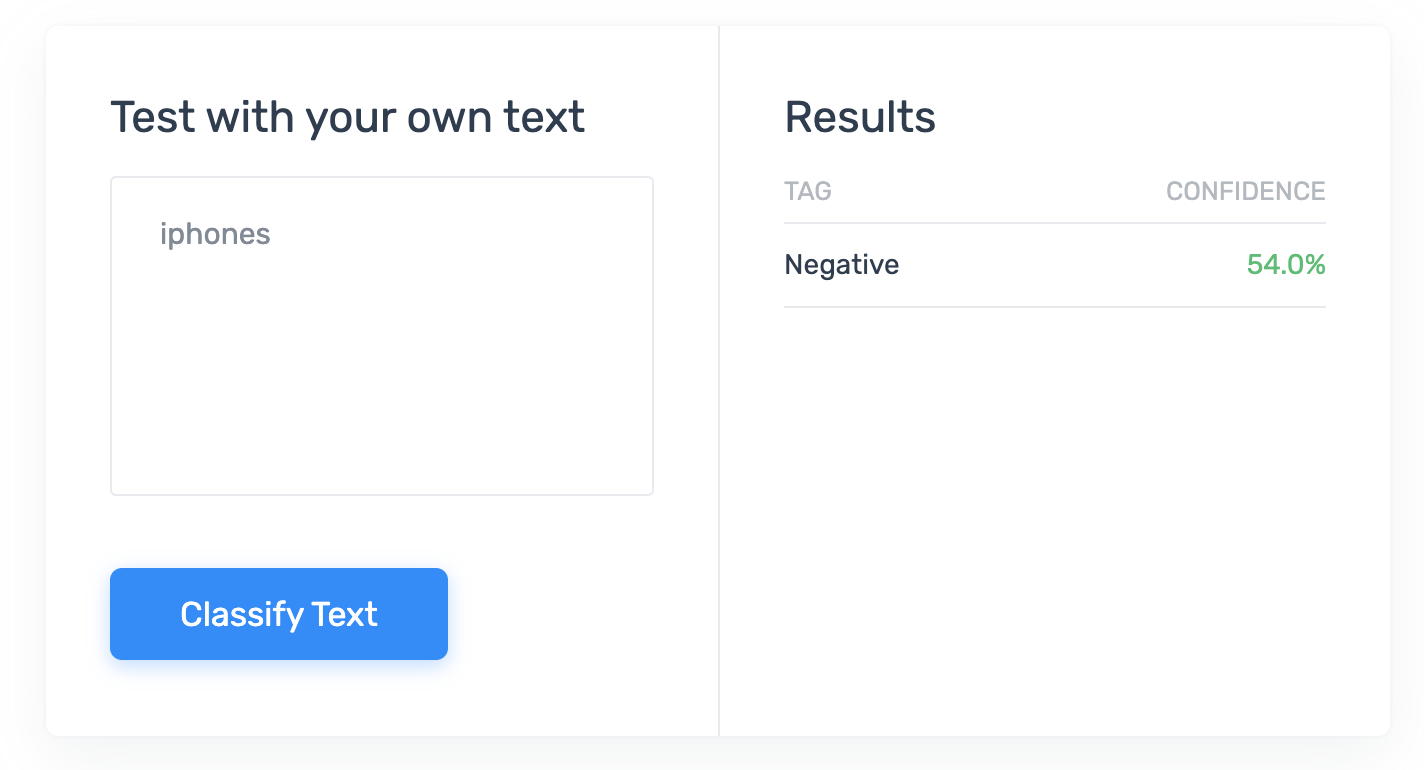
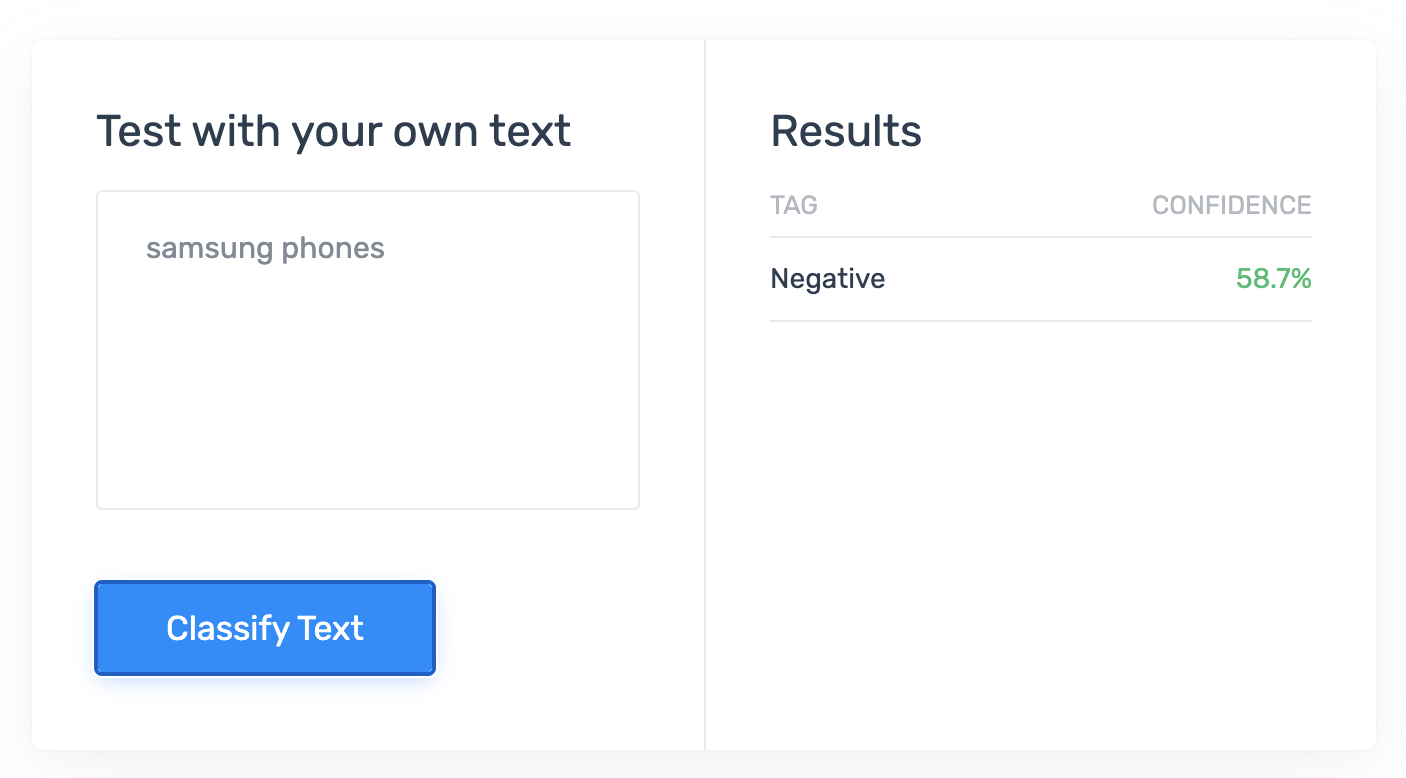
Sure enough, yes. Clearly they’re using context in their training data to extract some notion of negativity surrounding these devices, and “Samsung Phones” comes out slightly more negative.
The takeaway? There is no right or wrong answer here. Rather, context is king and sometimes it’s also impossible to ascertain intent from even long passages of text, never mind curt reviews. Sentiment analysis and natural language processing are tricky, for a host of good reasons I’ve shown above as well as a whole lot more I left out.
If you enjoy this topic, take a look at MonkeyLearn (no affiliation with Bennett Data Science) who wrote a terrific article on the topic here and have great demos you can plug your own text into.
Have a good week!
-Zank
Of Interest
We’re Getting Closer to Human-Level A.I.
Since the early decades of A.I., humanoid robots have been a staple of sci-fi books, movies, and cartoons. Yet, after decades of research and development, we still have nothing that comes close to the Jetsons’ Rosey the Robot. This is because many of our intuitive planning and motor skills are a lot more complicated than we think. Improvements, however, are being made. In a recent development in embodied A.I., several scientists developed a new challenge that will help assess the ability of A.I. agents in finding paths, interacting with objects, and planning tasks efficiently. Read more here.
A.I. is Learning how to Dodge Space Junk in Orbit
Every two weeks, spacecraft controllers at the European Space Operations Centre (ESOC) in Darmstadt, Germany, have to conduct avoidance manoeuvres with one of their 20 low Earth orbit satellites. There are at least five times as many close encounters that the agency’s teams monitor and carefully evaluate, each requesting a multi-disciplinary team to be on call 24/7 for several days, and the frequency of such situations is only expected to increase. The good news? An A.I.-driven space debris-dodging system is being developed to help. Read more here.
Greatest Female A.I. Influencers in 2021
Data science has proven to be successful in addressing a wide range of real-world issues, and is increasingly being used across industries to enable more intelligent and well-informed decision-making. There is a need for intelligent machines that can understand human actions and job habits as the use of computers for day-to-day business and personal operations expands. This pushes big data analytics and data science to the foreground. Unsurprisingly, women have made enormous advances in A.I. research in recent years. Here’s an overview of some of the greatest female A.I. influencers in the Data Science World in 2021.