
Generally, as companies scale, they create more data. If they’re data-driven, this means more costs, as compute power generally increases with increasing amounts of data.
In this week’s Tech Tuesday, I want to look at ways companies can handle large amounts of data without having to pay for massively-parallelized and expensive cloud computing.
One of the largest recommender systems on the planet is the YouTube recommender system. Imagine trying to recommend personalized videos to millions of people when hours of new content is uploaded to YouTube every second! That sounds dizzying, and it is. Typical approaches of ingesting all the data and using a monolithic recommendation engine would fail miserably. If they didn’t, they’d certainly be cost prohibitive.
So, YouTube does something ingenious that you can do as well; they pre-filter the world of videos to a smaller number that you might be interested in and rank those videos using a recommendation engine. YouTube calls this “candidate generation”.
Here’s their block diagram:
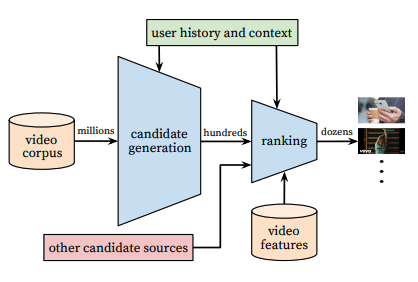
Note how the number of videos goes from millions of options to hundreds then dozens. Data scientists can work with hundreds of things to rank. Millions? That’s a lot harder, especially with the number of users YouTube has.
This is at a scale many of us will never see, yet this notion of pre-filtering (or generating good candidates) also applies to smaller companies with a lot less data.
Consider a company that wants to search documents for relevant content while assessing sentiment of the author. Then imagine the number of documents is in the tens of millions. That’s not too far outside the scope of many smaller companies. And processing this many documents to generate matches can generate high compute costs.
Here are a few things to consider with this trivial example that can cull down the number of documents that must be processed:
- How old is each document? If freshness matters, maybe only 30% of the documents are relevant.
- Does length matter? If so, how many documents have the required length?
- Does content type matter? If so, and you have metadata, the list can be shortened again.
I like to say that I don’t often work with “big data” because generally, when we look at applying algorithms to a specific problem, the size of the “right” data is generally rather small, as is the case with the YouTube recommender.
The next time you have a project that seems insurmountable or more expensive than you’d like, look for your own way to do “candidate generation” and make sure that your expensive compute power is only used to process the most relevant data.
Finally, as we’re growing and helping our clients achieve more with projects, we’re moving Tech Tuesdays to monthly. Look out for us on the first Tuesday of every month.
Until then, be well!
-Zank
Of Interest
A.I. Driving the Future of In-Car Systems
Driving while distracted, emotionally or otherwise, is dangerous. Even when a car is self-driving. Carmakers are bracing for new safety rules and standards around the world that could require dashboard cameras to detect dangerous driver behavior, especially in vehicles that are partly driving themselves but still need human attention. Read more here.
Machine Learning Tool Streamlines Student Feedback Process
On the heels of GitHub’s A.I.-driven Copilot project, Stanford professors develop and use a first-of-its-kind A.I. teaching tool that can provide feedback on students’ homework assignments in university-level coding courses, a previously laborious and time-consuming task. Read more here.
South Africa Issues World’s First Patent Listing A.I. as Inventor
South Africa has become the first country to award a patent that names an artificial intelligence as its inventor and the A.I.’s owner as the patent’s owner. The patent was secured by University of Surrey professor Ryan Abbott and his team, who have been at odds with patent offices around the world for years over the need to recognise artificial intelligences as inventors. Will this be the first of many? Read more here.