
by: Zank, CEO of Bennett Data Science
Recommenders are big business. I love them. I’ve designed algorithms that have shown billions of recommendations to tens of millions of users. Yet they don’t get a lot of attention in the media or the data science community. Look at this number: Netflix spends more than two-thirds of a billion (with a “b”!) on recommendations. They famously offered $1MM in what was called “The Netflix Prize” to make their recommendations just 10% (that 1/2 of one star) more accurate. It took large teams years to finally win. Then there’s Amazon, that patented the item-item collaborative filtering (CF) algorithm for recommendations (here’s a wonderful, simple, and now quite dated overview of CF from them). I don’t know what they spend on recommender science, but it must be up there with Netflix. Those are just two of the giants in the space.
In this post, I want to talk about what goes into an effective recommender and some of the challenges we face when building them.
How to Feed a Recommender
Generally speaking, recommenders can leverage three different data sources:
- Interaction data (what user consumed what product)
- User data (attributes)
- Item data (attributes)
Interaction data can be as simple as a list of user ID’s and the item ID’s those users purchased or browsed, etc.
Here’s an oversimplified view of an interaction matrix, sometimes called an adjacency matrix:
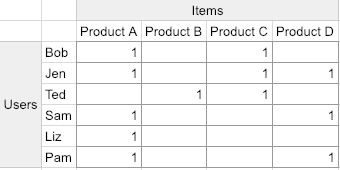
You can see the users are in rows and the products they’ve purchased are in columns. Notice there’s no indication of how much the user liked the product. This is sometimes the case. Remember when Netflix asked you to rate movies on a five-star system? Not anymore! They, behind the scenes, are estimating how much you liked what you watched based on many metrics such as: clicking to watch, continuing to watch, watching multiple episodes (when possible) etc. Here, we’ll just assume unary ratings; 1 if the user purchased the product and no value otherwise. Believe it or not, this is all we need to do a pretty good job of making recommendations.
When there’s enough interaction data, we can do things like say, “People like Bob also purchased product D”. Take a look at Jen, that’s her. This is at the heart of CF, and it’s very effective!
So, we’re done, right?
You’ve collected lots of interaction data and you built a CF recommender. Time to sail off into the sunset, right? Not exactly!
Remember the user and items data (we call those “side data”)? They’re about to come in really handy.
What happens when you want to make recommendations for a new product? A new user?
Imagine we create a new row for Jim (I’m a sucker for three-letter names). What do we recommend him?
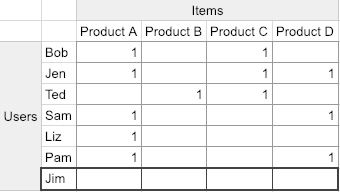
He has nothing in common with anyone else. So it appears that CF has broken down. Something similar happens when we insert a new column (product). It has never been purchased, so we don’t know how to recommend it to users. And these cases are where the user and item side data come in! Here’s how.
USERS
Imagine you have onboarding data for Jim. You’ve asked him questions about himself. Maybe these are demographics that describe Jim and all your users in a way that’s relevant to their purchasing behavior. Great, because that data will help us a lot for new users. Say for example that Jim’s onboarding data is very similar to that of Bob; then we can show Jim the products that Bob would be recommended. It’s not perfect, but it’s a start. And once Jim has his own purchase data, we don’t need to do this sort of thing.
ITEMS
Now let’s look at the items. Say we add a new product E (not very imaginative, I know) and through product side data (its attributes, like price, color, size, etc) we know that it’s just like product C. This allows us to recommend new product E everywhere we might recommend product C. We can continue like this until product E has enough interaction data that we no longer have to give it special treatment.
This process solves what is known as the cold start problem.

To be complete, there are recommenders that incorporate all three data sources. One of the best is a factorization machine. When set up correctly these recommenders are some of the most accurate solutions available to the recommendation problem.
I hope you enjoyed this vastly oversimplified overview of one of my favorite topics, recommender systems.
Want to learn more about recommenders? There’s always the yearly Recommender Systems Conference, Recsys! I recommend it! (couldn’t resist)
Zank Bennett is CEO of Bennett Data Science, a group that works with companies from early-stage startups to the Fortune 500. BDS specializes in working with large volumes of data to solve complex business problems, finding novel ways for companies to grow their products and revenue using data, and maximizing the effectiveness of existing data science personnel. bennettdatascience.com