
by: Zank, CEO of Bennett Data Science
Yeah, that’s right they are. At least they should be!
I’m talking about predictive models. These are the things you put some data into, and they spit out an answer for you. Think of them like those 8-balls you shake and viola, there’s your answer. Data scientists build them for your business and they help you forecast. More on that below.

But unlike that 8-ball, predictive models require new data from time to time. So, what’s the shelf life of a predictive model?
This is a great question, and one that I might not have thought much about if a smart colleague hadn’t asked me a related question earlier today. It got me thinking, especially given all the predictive work we do. One of our early concerns when starting a project is: What’s the shelf life of a predictive model?
Let’s get into what that means and find some answers
Generally speaking, data scientists build “models” that predict stuff. For example, we might predict whether a customer will churn, or if a customer wants this product or that one, or if Bob should date Sarah, and so on.
Models predict the relationship between input and output data and are made from a collection of training data. Once created (or trained), a model takes some new data as an input and produces an output called the prediction. That might sound confusing. Let’s look at a simple example.
Say we want to build a model that predicts how many umbrellas an amusement park needs to buy for a given amount of rainfall. For this scenario, let’s assume we believe the weather forecast for the following month in terms of how much rain will fall (it’s a bit far fetched, but bear with me ????)
The park doesn’t want to buy too many or too few umbrellas. So, we collect a bunch of data from the previous year. Here’s what that might look like (with simulated data) below:
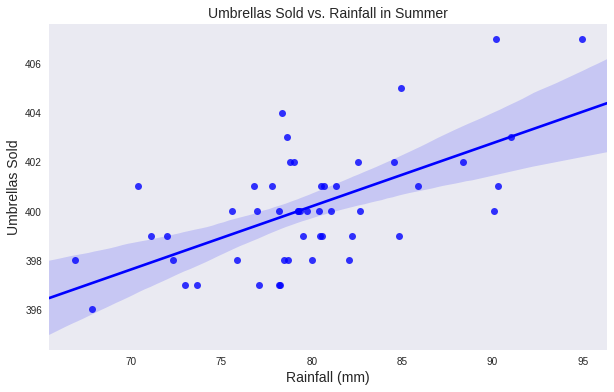
The solid line is our prediction. That’s our “model”.
It’s clear that we can predict how many umbrellas we’ll need for a given amount of rainfall, with a certain amount of accuracy. We can even use this “model” to predict areas that are outside this window, for example, 50mm of rain. This is fantastic, especially considering our data never had a value associated with 50mm! That’s the insightful value of predictive modeling.
This model will continue to work fine assuming that conditions don’t change. In other words, its accuracy should be relatively constant. We’d be prepared to sell umbrellas to all our visitors without undue inventory if we used this particular model…except. Well, except when conditions change, literally.
Let’s take a look at what happens in Winter. Again, this is synthetic data I dreamt up to make my point
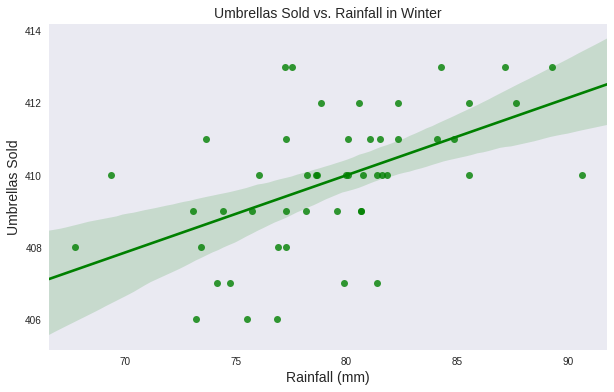
It looks really similar. A keen eye will notice that more umbrellas were sold for roughly the same amounts of rain. So, when it’s cold and rainy, it looks like visitors are more sensitive to the rain and are more likely to purchase an umbrella for all amounts of rainfall. So what does this mean?
Well, the first model was appropriate, until it wasn’t; until conditions changed. That’s the entire argument for retraining data science models.
Depending on the business case, model training can occur as infrequently as weekly, or as frequently as each time there’s new data (which can be multiple times per second). From my experience, nightly training is quite common.
To motivate the need for model re-training on the most relevant data, imagine how inaccurate our summer model would be in winter and vise versa, when they’re both on the same plot:
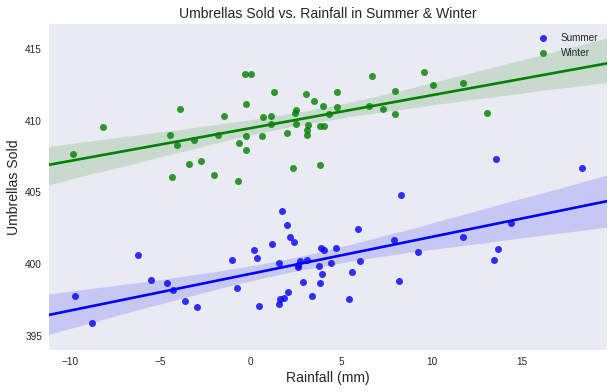
The differences here are small, and meant only to motivate the need to have up-to-date predictive models.
The take-home: models are only as good as the data that went into them; And when things change, new models need to be created.
Here are some of what a data scientist does daily to keep the wheels on predictive models like this:
- Set up and monitor model training and subsequent (daily) automated retraining
- Monitor data for fundamental changes (a very cold summer, for example)
- Look for ways to incorporate new/different/more data to increase model accuracy, such as seasonal trends
Of course, this is just a small list, and only related to a simple/trivial model. In practice, models can have hundreds to tens of thousands of inputs (here, it’s only two) and require careful monitoring and frequent retraining and, less frequently, re-tuning.
Data scientists play a fundamental role in making sure predictive analytics stay in pace with changes to the data. This is just one example. I hope it helps shed some light on what is often a nebulous topic.
Zank Bennett is CEO of Bennett Data Science, a group that works with companies from early-stage startups to the Fortune 500. BDS specializes in working with large volumes of data to solve complex business problems, finding novel ways for companies to grow their products and revenue using data, and maximizing the effectiveness of existing data science personnel. bennettdatascience.com