
by: Zank, CEO of Bennett Data Science
Models and why they are fundamental
I want you to know what a predictive model really is. It’s important. Once you see how simple it is, I think it will help unlock a lot of the confusion surrounding data science. But there’s another reason I want you to know; models are fundamental to what we do and this understanding is essential to enabling data scientists on your team to be successful.
Of the epiphanies I’ve had over the past few years, perhaps none is more foundational than this; Most data scientists don’t know what a model is. Don’t believe me, ask one. Seriously. Every single data scientist I know will provide an answer, but most are vague descriptions of what a model really is and I’ve yet to hear anyone nail it. This is a huge pain point, because it’s this confusion that often creates roadblocks when data science interacts with other teams. I’ve asked a room of hundreds of data scientists…crickets. It’s a tough question. And I have no idea why!
To start, here’s what Google has to say:
#3 sounds good, but it’s quite abstract. Let’s see if it passes the test of putting it into a common use case: Let’s say you’re talking to your head of IT, Sarah: “Hi, Sarah. Would you help our data scientist to deploy the simplified description, especially a mathematical one, of a system or process, to assist calculations and predictions?” Um, that sucks. Not even close. We’ve got some work to do. Stick with me, I promise this is worth it!
When a data scientist is talking about a models, she’s generally talking about predictive models, like a churn model or a recommender model. Let’s say a data scientist is talking with someone in IT to get a predictive model deployed so it can be used to “predict stuff” in production. This is something many data scientists need to do all the time.
A simple example
Let’s back up. All the way back to high school algebra, or, if you prefer, that revenue chart you were last working on. We’re going to make a dead-simple model and work towards the definition from there. Then we’re going to use the case of communicating to IT and see why understanding this simple case is so important to understanding and enabling data scientists.
Here’s our simple example. It’s a linear fit line to the equation: y = mx + b. Remember that old equation from high school algebra? ????
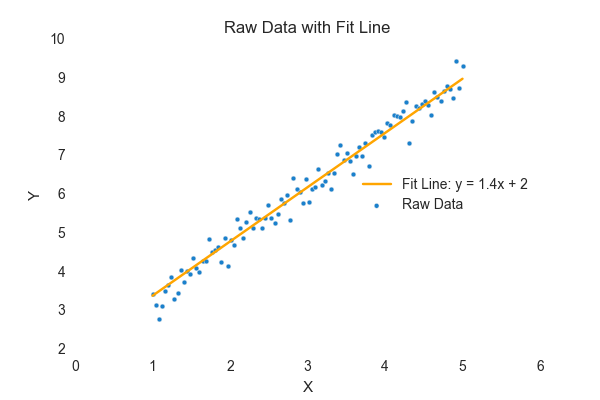
This plot shows what a simple example might look like. Notice the line takes the form: y = 1.4x + 2.
There’s no math involved to see that m = 1.4 and b = 2. And right there, we’ve completely described that orange line. Just those two coefficients. It’s nothing more than that.
This simple equation, y = 1.4x + 2 allows us to predict y from any given value of x. Here’s the (not so dramatic) finale: the m and b are model coefficients and y = 1.4x + 2 is the model.
When a data scientist refers to a model, she’s not referring to all those blue data points or to anything abstract at all; she’s talking about the ‘1.4x + 2’ part. I’ll make it MUCH simpler. The takeaway here: is that only the values for m and b need to be stored to reproduce that orange line. That orange line “models” the blue data points. So the person in IT who wants to enable the data scientist to make predictions only needs to store and retrieve the m and b. To someone in IT, those coefficients are the model. This is foundational, because anyone in IT will understand this. And wow is it fun to see the light come on and to watch teams start working together instead of confusing each other!
But wait, you demand, it has to be more complex than that. Sure it definitely is, and we can make it more complex. For example, maybe there are a lot of m’s. Ok, for three m’s the model looks like this:
y = m1x1 + m2x2 + m3x3 + b
It’s just more simple (and fast) to compute multiplies and adds.
Models are collections of coefficients that power (predictive) equations
They aren’t orbs of light or messages from above. They’re just this simple. The equations can get really tricky, there can be tens of thousands of these coefficients; but at the end of the day, computers can only add and multiply, and it’s the job of the data scientist to solve for the coefficients that power these powerful models.
This is a talk I love to give, and one that I’m quite passionate about. I’ll link here to a video I’m planning on doing to cover this exact topic.
Zank Bennett is CEO of Bennett Data Science, a group that works with companies from early-stage startups to the Fortune 500. BDS specializes in working with large volumes of data to solve complex business problems, finding novel ways for companies to grow their products and revenue using data, and maximizing the effectiveness of existing data science personnel. https://bennettdatascience.com/staging