
I just searched Google for “Data Science Articles” and got back 2,970,000,000 results. Whoa! That’s a lot of results. That’s a lot of analysis. How much is conjecture? Speculation? How much was peer-reviewed? You get it. The answer is, we don’t know.
Who cares? Well, when the work involves predicting customer purchase behavior, maybe the consequence of weak or insignificant results is small. But what about A.I. that drives cars or predicts cancer or informs countries about the progression of a pandemic? What if millions of people read it?
Then it matters.
The (perceived) credibility of data science
Data science results often look very credible, with charts and graphs and proclamations and all those numbers and statistics… One is tempted to think that the person who did the work must be a genius! Hmm. We need to be careful.
Take this chart, for instance, showing the number of COVID-19 cases in the UK:
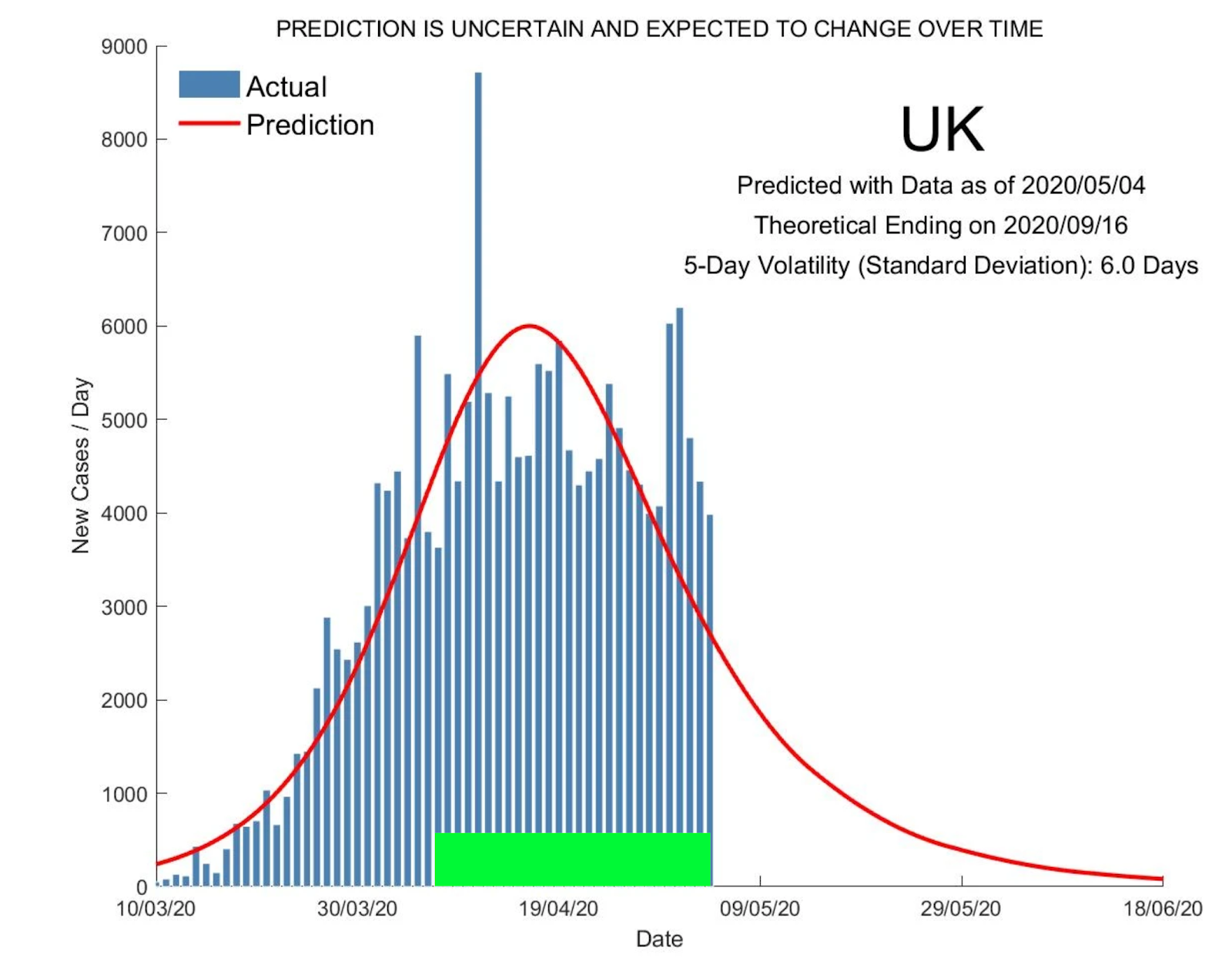
The red curve is supposed to predict the blue curve. Do you think it does so far? Do you believe that there will no more COVID-19 cases in the U.K. as of June 18th? We certainly don’t. And we should never rely on this chart to indicate the end of COVID-19.
What’s wrong with the chart?
For one, the red curve is a predictive model, designed to closely match the tops of blue bars, and predict their future heights. Yet it doesn’t. And it’s not even close (forget that tall outlier in blue). The red curve is also perfectly symmetrical, but as we can see, the blue bars don’t show that same symmetry.
Also, take a look at the heights of the blue bars above the region I marked in green. The heights of the blue bars oscillate but do not drop the way the red curve does. Hence, the red curve does not reflect the actual data and is a horrible choice for tracking the number of COVID-19 cases.
That’s certainly no fault of the authors. In fact, to their credit, the spread of viruses is “supposed” to follow this curve (if you must know, the red curve is the derivative of the sigmoid curve, typically used to model infections. It’s the same model we initially used for our graphs until it stopped working.)
As our work has shown, countries are recovering differently than we could have predicted from COVID-19. Recovery is taking a lot longer than any person or model expected and it’s up to the authors to get that right or pull their models off the internet.
Results like these are misleading at best and unfortunately, they’re all too common.
The democratization of data science
With all that said, there’s a big push towards something called the “democratizing data science”. The premise is that smart folks with more access to predictive tools can do a lot of good, and that empowering them with easy-to-use versions of powerful A.I. will, therefore, bring about many benefits.
And there is certainly value to doing this! But very, very carefully. And only with senior-level oversight. Data science requires peer review, mentorship, and well-intentioned skepticism.
As an undergraduate at UCSD back in the day, I took a class called biostatistics where we spent (only!) one day discussing ethics. I still remember how horrified I was to learn about the possible repercussions of incorrect/misleading data presentation and the importance of having (statistical) confidence in results.
The questions I asked myself back then are still crucial today: How can we be sure our results are rigorous? Or better yet, when they don’t hold up to scrutiny, how can we be sure there’s a competent scientist around to make the required adjustments or throw the model out altogether?
This is why I bring up the idea of a license to use A.I.
Of course, I don’t think we should go to some local Department of Artificial Intelligence (DAI) and wait in horrendously long lines to get a type of “A.I. driver’s license”. That would be absurd.
But here’s something else equally as absurd: hiring data scientists right out of graduate school, giving them near zero oversight or mentorship, and expecting them to deliver robust predictive models that drive company insights and revenue in 20 weeks. More often than not, they fail because data scientists require years of real-world experience to be effective.
The solution
The solution is to provide senior level guidance and mentorship. I’ve written an article about the undeniable value young data scientists get from mentorship. I can’t imagine where I’d be without it.
As we’re all likely watching a lot of news and hearing projections of what the “new normal” will be, I invite you to listen with a bit of healthy skepticism. Find the voices out there you believe; the ones who are consistently careful with their words.
And when you’re embarking on data science projects of your own, make sure you have some level of senior oversight. It really makes the difference between long-term success and short- or middle-term failure.
If this brings up some questions about your team or analytics projects, contact us, and let’s have a chat. We’d be happy to discuss this with you further!
Be well,
Zank and the Bennett Data Science team
Of Interest
Music Generated From Neural Nets – the Best Yet
Jukebox is a neural net that generates music, including rudimentary singing in a variety of genres and artist-styles. Try it yourself! The article includes the model weights and code, along with a tool to explore the generated samples. You won’t believe how close we are to completely computer-generated music, with vocals.
https://openai.com/blog/jukebox/
A Rigorous Look at the Foundations of Data Science
Relevant to this week’s Tech Tuesday, this article offers a rigorous look at the foundations of data science. Transdisciplinary Research In Principles Of Data Science (TRIPODS) brings together the statistics, mathematics, and theoretical computer science communities to develop the theoretical foundations of data science through integrated research and training activities focused on core algorithmic, mathematical, and statistical principles.
https://annals.org/aim/fullarticle/2088542/transparent-reporting-multivariable-prediction-model-individual-prognosis-diagnosis-tripod-explanation
This Researcher’s Observation Shows the Uncomfortable Bias of TikTok’s Algorithm
A small experiment by an artificial intelligence researcher is raising questions about how TikTok’s recommendation algorithm suggests new creators to users. Specifically, the question raised is whether the algorithm is sorting suggestions based on the race of the creator.
https://www.buzzfeednews.com/article/laurenstrapagiel/tiktok-algorithim-racial-bias