
With the measures undertaken to battle COVID-19, companies and universities find themselves shuttered and not opening anytime soon. As a result, people are increasingly turning to online education to learn something new or brush up on some old skills. And more and more often, I’m asked to recommend the best class(es) to learn the fundamentals of data science.
This week, I will share what I always tell anyone who wants to learn data science and discuss my favorite interview question for anyone who wants to work for me as a data scientist. I’ll keep it short and to the point, and believe that this will be really helpful to you as it briefly outlines the elementary skills you need along with several easy steps to get you started.
And if it doesn’t apply to you, consider forwarding this to a colleague, family member, friend or neighbor that you think might benefit from it. Thanks if you do!
Let’s jump in.
STEP ONE
Start by answering this essential question:
When should you use machine learning or A.I.?
I believe one of the best answers to that foundational question can be found in the aptly titled, Rules of Machine Learning, written by dozens of highly knowledgeable scientists at Google. I’ve never read anything better on the topic. Take a look at the guide’s first rule:
Rule #1: Don’t be afraid to launch a product without machine learning.
It shakes up what many believe: that A.I. is somehow a panacea for any ailment our products or processes have. It’s not! And this guide makes that very clear.
STEP TWO
The next step (since the first one only takes about 30 minutes) is to learn Python while learning data science. This will be a brick-wall learning curve but, with dedication, it can be done. I’ve seen it firsthand and the results were spectacular.
To do this:
- Go here to download then install Anaconda Python (completely free). Anaconda makes it simple to install Python and get running quickly.
- Next, figure out how to launch and use Jupyter Notebooks.
- As soon as you have notebooks working, take Andrew Ng’s Coursera class Intro to Machine Learning. It will take weeks but it’s free and the class has over 130,000 reviews with an impressive and well-deserved 4.9 average star rating. It’s an older class but still covers the fundamentals really, really well. Andrew Ng is a master and, not unimportantly, he’s kind in how he teaches. But, and here’s the big catch, it’s taught in a scripting language called Matlab.
- Whether you’re a Matlab wiz or not (and I’ve got 20,000+ hours of Matlab under my belt), please don’t do any of the work in Matlab. Matlab is not what most data scientists use. Do it in Python. Here’s how:
-
- Grab all the class programming assignments that someone kindly ported over from Matlab to Python
- As you learn, work through all the examples yourself using those Python skeleton scripts
This will be more difficult, as you won’t have the added help of the Matlab-based lectures, BUT will be much, much better for you as Python is is a highly productive and more commonly-used programming language compared to others.
STEP THREE
Next up, take an overview class on basic statistics. I don’t have a particular resource for this, but a good understanding of statistics is essential for data science and there are a lot of free classes available online.
To demonstrate why statistics is so important, here’s my all-time favorite interview question for introductory to mid-level analytics applicants:
Take a look at the following distribution of points and quickly tell me, what is the average?
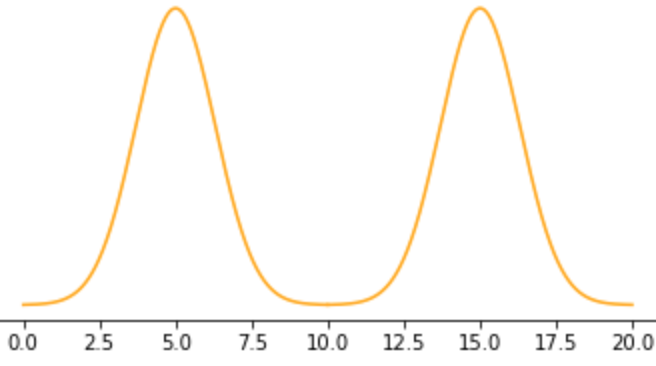
It’s a trick question! If you said, “it can’t be done”, you’re exactly right. You can, of course, compute the average, but the result (10) would be nonsense since the distribution isn’t what we call a Gaussian distribution (sometimes called a “normal” distribution or a bell-shaped distribution). Since it’s not Gaussian (and not even close), the “average” is not defined and so the result is meaningless. Data scientists have to know these things.
Hence, the reason this is my favorite interview question is because it indicates whether the interviewee looked carefully enough and understood the underlying data. Good data science starts with a strong understanding of the available data and generally ends with good descriptors of that data. Those descriptors turn into models, and models built on junk are junk. In other words, if I’m going to hire someone it is essential that they have a good understanding of statistics. They have to know the answer to this question.
What can be gathered from all this is that becoming a good data scientist takes time, skills, and perseverance. If you are planning to take this path to learn more about analytics, feel free to reach out. I hope these tips and suggestions will help you!
Be well,
Zank
Of Interest
How A.I. is Changing Fashion: Impact on the Industry with Use Cases
Here’s an interesting article on one of my favorite topics for A.I. – Fashion. A.I. is everywhere in the > $3 Trillion fashion industry, from design to the supply chain to online and physical stores. This article gives an interesting overview of many different use cases for A.I. in the industry:
https://medium.com/vsinghbisen/how-ai-is-changing-fashion-impact-on-the-industry-with-use-cases-76f20fc5d93f
Microsoft Used Machine Learning to Make a bot That Comments on News Articles for Some Reason
The social internet has a bot problem. Fake accounts plague Twitter and Facebook, and content designed to misinform readers has become an issue that’s drawn the attention of Congress. This difficult and growing problem hasn’t stopped a team of researchers at Microsoft from creating an algorithm that can parse news stories, then bicker with real humans in the comments section.
https://www.vice.com/en_us/article/d3a4mk/microsoft-used-machine-learning-to-make-a-bot-that-comments-on-news-articles-for-some-reason
Why Machine Learning Deployment is Hard
Deploying Machine Learning (ML) models at scale is one of the most most important and challenging objectives for companies seeking to build value through A.I., and as models get more complex it’s only getting harder. This article addresses some of the challenges.
https://towardsdatascience.com/why-is-machine-learning-deployment-hard-443af67493cd